Regressão Linear
A operação Regressão Linear tem como objetivo criar um modelo, que é basicamente uma função linear. A ideia desta operação é criar uma linha reta irá minimizar a soma dos quadrados dos resíduos entre as respostas observadas na base de dados e as respostas preditas pela aproximação linear. O modelo produzido pela operação Regressão Linear assume que os resíduos seguem uma distribuição Gaussiana.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e modelo do algoritmo de regressão |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo(s) previsor(es) | Atributo que será usado para treinamento |
| Atributo com o rótulo | Atributo a ser predito |
| Atributos com a predição | Atributo contendo a predição do modelo |
| Iterações máximas | Define o número máximo de iterações para a convergência do algoritmo. O seu valor padrão é 100 |
| Regularização | Define o valor para regularizar o ajuste da função de perda do algoritmo. O seu o valor padrão é 0 |
| Mix. para ElasticNet (entre 0 e 1) | Parâmetro de ajuste usado para a minimização da função objetivo usando uma combinação de L1 e L2. O seu valor por padrão é 0 |
| Solucionador (Solver) | Define o algoritmo para gerar a solução da otimização do problema de regressão. O seu valor padrão é ‘auto’, significando que isso será feito automaticamente pelo algoritmo de regressão linear |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
Definições
Resíduos
É a diferença entre os valores observados na base de dados e as respostas preditas pelo modelo. Por exemplo, se queremos saber/predizer a receita de uma loja em um dia considerando como atributo a temperatura máxima daquele dia, os resíduos seriam:
| Temperatura (Celsius) | Receita (Observado) | Receita (Predito) | Resíduo (Observado - Predito) |
|---|---|---|---|
| 28.2°C | R$44,00 | R$41,00 | R$3,00 |
| 21,4°C | R$23,00 | R$23,00 | R$0,00 |
| 32,9°C | R$43,00 | R$54,00 | -R$11,00 |
| 24,0°C | R$30,00 | R$29,00 | R$1,00 |
Exemplo de Utilização
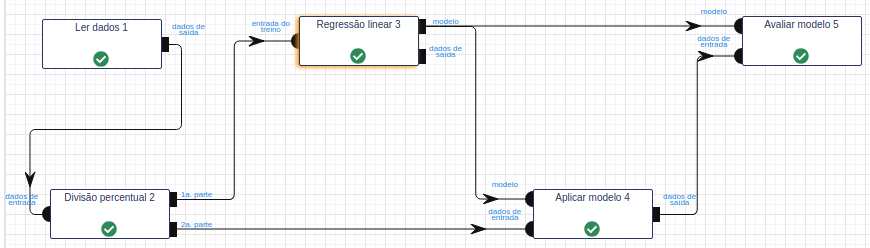
Objetivo: Utilizar o modelo construído pela operação Regressão Linear para predizer a qualidade de um vinho.\ Base de Dados: Qualidade da Variante Vermelha do Vinho Verde Português - Wine Red Quality
-
Leia a base de dados por meio da operação Ler dados.
-
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Percentual, calibre-o utilizando 50% dos dados para treinar (1.ª parte) e 50% para testar (2.ª parte).
-
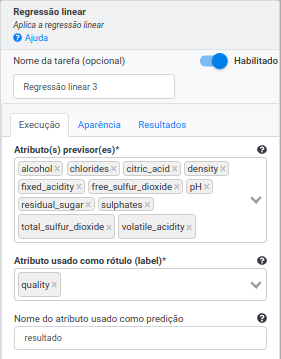
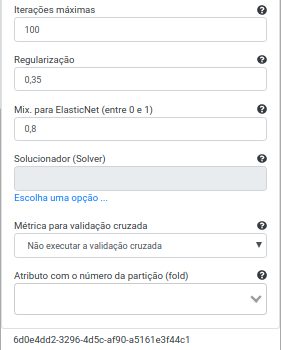
Na Operação Regressão Linear, selecione “alcohol”, “chlorides”, “citric_acid”, “density”, “fixed_acidity”, “free_sulfur_dioxide”, “pH”, “residual_sugar”, “sulphates”, “total_sulfur_dioxide” e “volatile_acidity” no campo Atributo(s) previsor(es). Selecione “quality” no campo Atributo com o rótulo e preencha “resultado” no campo Atributo com a predição (novo). Preencha 100 no campo Iterações máximas, 0.35 no campo Regularização e 0.8 no campo Mix. para ElasticNet. Deixe os demais parâmetros inalterados.\
-
Na operação Aplicar Modelo, selecione “alcohol”, “chlorides”, “citric_acid”, “density”, “fixed_acidity”, “free_sulfur_dioxide”, “pH”, “residual_sugar”, “sulphates”, “total_sulfur_dioxide” e “volatile_acidity” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo (herdado do modelo).
-
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “quality” no campo Atributo usado como label e a métrica “Raiz do erro quadrático médio” como Métrica para avaliação.
-
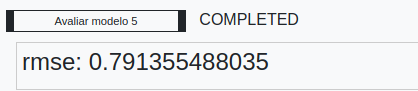
Execute o fluxo e visualize o resultado, que neste caso está de acordo com a raiz do erro quadrático médio (Root Mean Square Error ou RMSE):
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br