Gradient Boosted Tree
A operação Gradient-Boosted Trees (GBT) possui como objetivo criar um modelo baseado em ensembles de Árvores de decisão. Para isso, o GBT iterativamente treina (a partir de uma base de dados de entrada) um conjunto de árvores de decisão minimizando uma dada função de perda. A ideia do GBT é criar vários modelos (de árvore de decisão) considerados mais simples (ou fracos) a fim de criar um modelo mais poderoso e robusto, por combinar resultados desses vários modelos fracos. Atualmente, somente suporta problemas de classificação multi-classe (i.e., com mais de duas classes) caso seja realizada classificação um-contra-todos.
Conectores
| Entrada | Saída |
|---|---|
| Dados utilizados para treinar o modelo | Dados de saída e Modelo do algoritmo de classificação |
Tarefa
Nome da Tarefa
Aba Execução
| Parâmetro | Detalhe |
|---|---|
| Atributo(s) previsor(es) | Atributo(s) que será(ão) usado(s) para treinamento |
| Atributo com o rótulo | Atributo a ser classificado |
| Atributos com a predição | Atributo contendo a predição do modelo |
| Pesos | Pesos do algoritmo em um ensemble |
| Manter identificadores dos nós em cache | Se selecionado, o algoritmo evita passar o modelo atual para os executores da próxima iteração |
| Intervalo para checkpoint (cache) | Frequência com a qual fazer checkpoints |
| Tipo de perda | Função de perda a ser minimizada. Atualmente, somente a função logística está disponível para esta operação |
| No. máximo de bins | Número de bins utilizados quando discretizando uma variável contínua |
| Profundidade máxima | Profundidade máxima permitida nas árvores de decisão |
| Taxa de subamostragem | Fração do conjunto de dados que será passado para cada árvore |
| Iterações máximas | O número máximo de iterações do algoritmo boosting |
| Ganho mínimo de informação | Mínimo de information gain para que haja a utilização de uma feature na divisão de um nó |
| Mínimo de instâncias por nó | O número mínimo de instâncias (exemplos) que precisam estar em um nó folha de cada árvore. O seu valor padrão é 1 |
| Tamanho do passo | Tamanho do passo a ser utilizado em cada iteração do GBT |
| Métrica para validação cruzada | Define a métrica utilizada dentro da validação cruzada (se aplicável) para avaliar o modelo de classificação dentro das k partições |
| Atributo com o número da partição (fold) | Define o atributo a ter o número da partição para realizar uma validação cruzada (se aplicável) |
| Usar classificação um-contra-todos (one-vs-rest) | Se selecionado, o algoritmo realizará classificação um-contra-todos ao invés de classificação tradicional (neste caso, binária) |
Exemplo de Utilização
Objetivo: Utilizar o modelo do Gradient Boosted Tree (GBT) para classificar se uma pessoa possui ou não a doença diabetes.\ Base de Dados: Pima Indians Diabetes
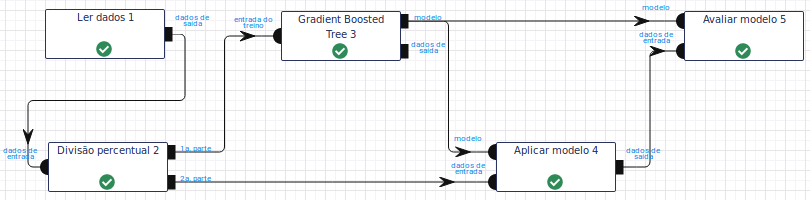
-
Leia a base de dados por meio da operação Ler dados.
-
Utilize a operação Divisão percentual para dividir a base de dados em treino e teste. No parâmetro Percentual, calibre-o utilizando 50% dos dados para treinar (1.ª parte) e 50% para testar (2.ª parte).
-
Na operação Gradient Boosted Tree, selecione “Age”, “BMI”, “BloodPressure”, “DiabetesPedigreeFunction”, “Glucose”, “Insulin”, “Pregnancies” e “SkinThickness” no campo Atributo(s) previsor(es). Selecione “class” no campo Atributo com o rótulo e preencha “resultado” no campo Atributo com a predição (novo). Deixe os demais parâmetros inalterados.\
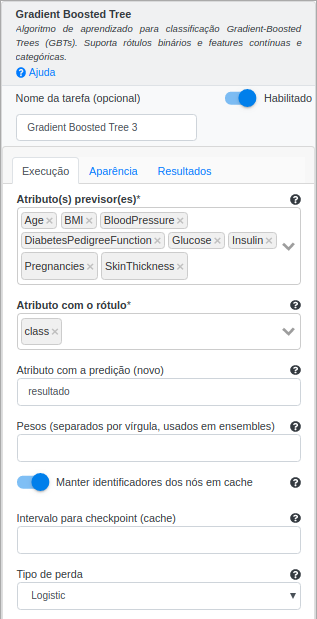
-
Na operação Aplicar Modelo, selecione “Age”, “BMI”, “BloodPressure”, “DiabetesPedigreeFunction”, “Glucose”, “Insulin”, “Pregnancies” e “SkinThickness” no campo Atributo(s) previsor(es) e preencha “resultado” no campo Nome do novo atributo (herdado do modelo).
-
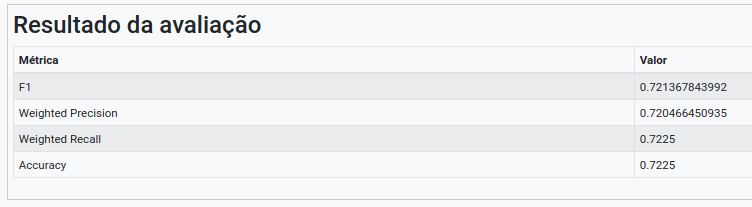
Na operação Avaliar Modelo, selecione “resultado” no campo Atributo usado para predição. Selecione “class” no campo Atributo usado como label e a métrica “F1” como Métrica para avaliação.
-
Execute o fluxo e visualize o resultado, i.e., a matriz de confusão gerada para as predições do modelo de árvore de decisão e, consequentemente, a tabela representando as métricas de classificação (derivadas da matriz de confusão).\
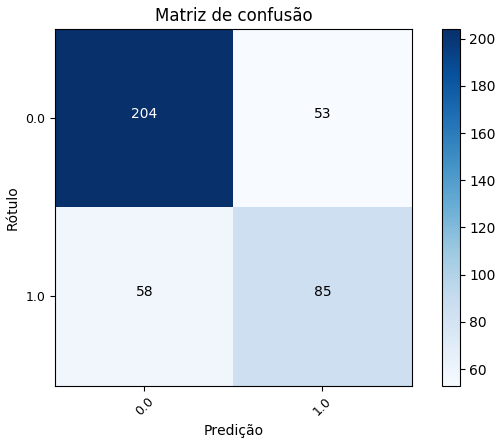 \
\
Dúvidas e/ou sugestões envie um e-mail para suporte@lemonade.org.br